又一个社会关系在计算机逻辑设计中的体现。
什么是zookeeper?
Zookeeper是一个分布式协调服务,为分布式系统系统提供共享配置,协调资源,提供命名服务等;
那什么是分布式系统?**
合起伙来办大事;
一件事情一个人做需要几个小时,几个人一起做可能几分钟就能完成。这几个人就是“集群”,集群中的每个独立个体就是“节点”。
集体的优点:
- 集群中几个节点思想出了问题,对整个集群影响不是很大。
- 集群可以通过补充节点不断壮大。
- 节点可能代表整个集群的形象。
集群的问题:
- 共享资源存在竞争。
- 死锁,几个节点相互等待对方的结果才能进行下一步。
- 数据不一致。
Zookeeper的数据模型:
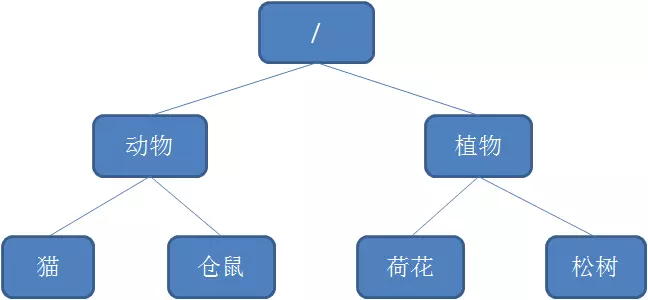
Zookeeper数据模型是树形结构,不同于树,Zookeeper使用路径引用,比如猫就是 “ /动物/猫”
Znode数据模型:
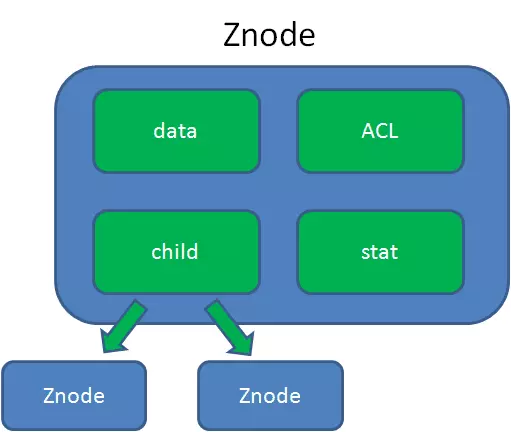
data:
Znode存储的数据信息。
ACL:
记录Znode的访问权限,即哪些人或哪些IP可以访问本节点。
stat:
包含Znode的各种元数据,比如事务ID、版本号、时间戳、大小等等。
child:
当前节点的子节点引用,类似于二叉树的左孩子右孩子。
Zookeeper是为了应对读多写少的场景的,所以节点信息不易频繁改变,并且节点数据最大不能超过1M。
基本操作和时间通知API:
cteate、delete、exists、getDate、setDate、getChildren
watch?**
客户端访问Znode时,会维护一张watchTable,key为Znode路径,value为watcher;
当Znode改变时,异步通知watcher,并删除watchTable中对应的key-value
zookeeper Service
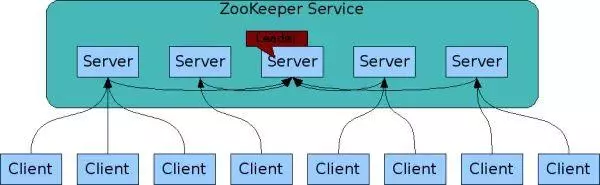
服务器:分为follow和leader,follow只读,leader读写;
客户端:向follow服务器请求;
常规数据更新步骤:
- 客户端发起写入请求给follower;
- follower把请求转发给leader;
- 二次提交:leader告诉所有follower,半数以上follower写入成功后,通知客户端写入成功;
- leader再发送commit广播给follower;
崩溃恢复:
leader这么重要,要是leader崩溃了会怎么样?先了解下节点状态
节点状态:looking、leading、following;
最新事务ID:ZXID
崩溃恢复的步骤
- 选举阶段:
- 状态都置为looking,向其他节点发起投票,投票信息包含自己的节点ID和最新事务ID(ZXID)
- 发现ZXID比自己大时重新发起投票,投票给当前最大ZXID的节点;
- 节点会统计投票数量,某个节点半数以上投票时,这个节点状态置为leading,其他节点置为following;
- 发现阶段:
- 从所有节点中寻找最新事务,接收follow发过来的epoch,+1,再发回follow;
- follower接收到之后返回ACK,带上XZXID和事务日志,leader选出最大ZXID,并更新自身日志;
- 同步阶段:
- 将最新事务日志同步给所有follower,半数以上follower同步成功才成为正式leader
用途:
- 分布式锁
- 服务注册和发现
- Dobbo
- 共享配置和状态信息:
- Redis的分布式解决方案Codis;
- Kafka、HBase、Hadoop